The ScrapeGraphAI app for Zapier connects any Zap to ScrapeGraph’s v2 API as native Zapier actions — fetch pages, extract structured JSON, run web searches, kick off multi-page crawls, and schedule monitors. Pair it with Zapier’s 7,000+ apps to wire scraping into Slack, Sheets, Notion, Airtable, HubSpot, or anything else.
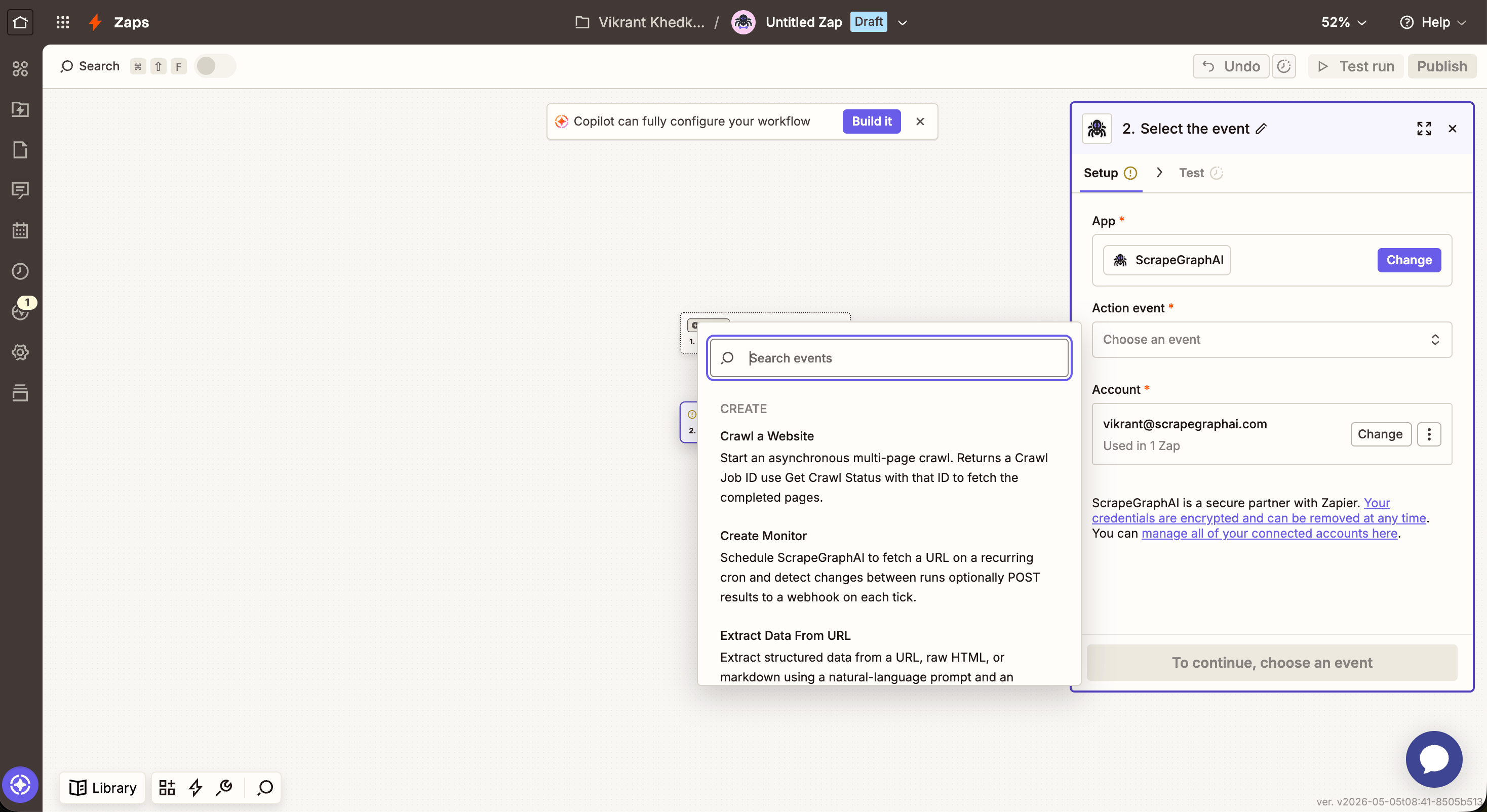
In any Zap, search for ScrapeGraphAI as an action and pick one — for example Scrape a URL.
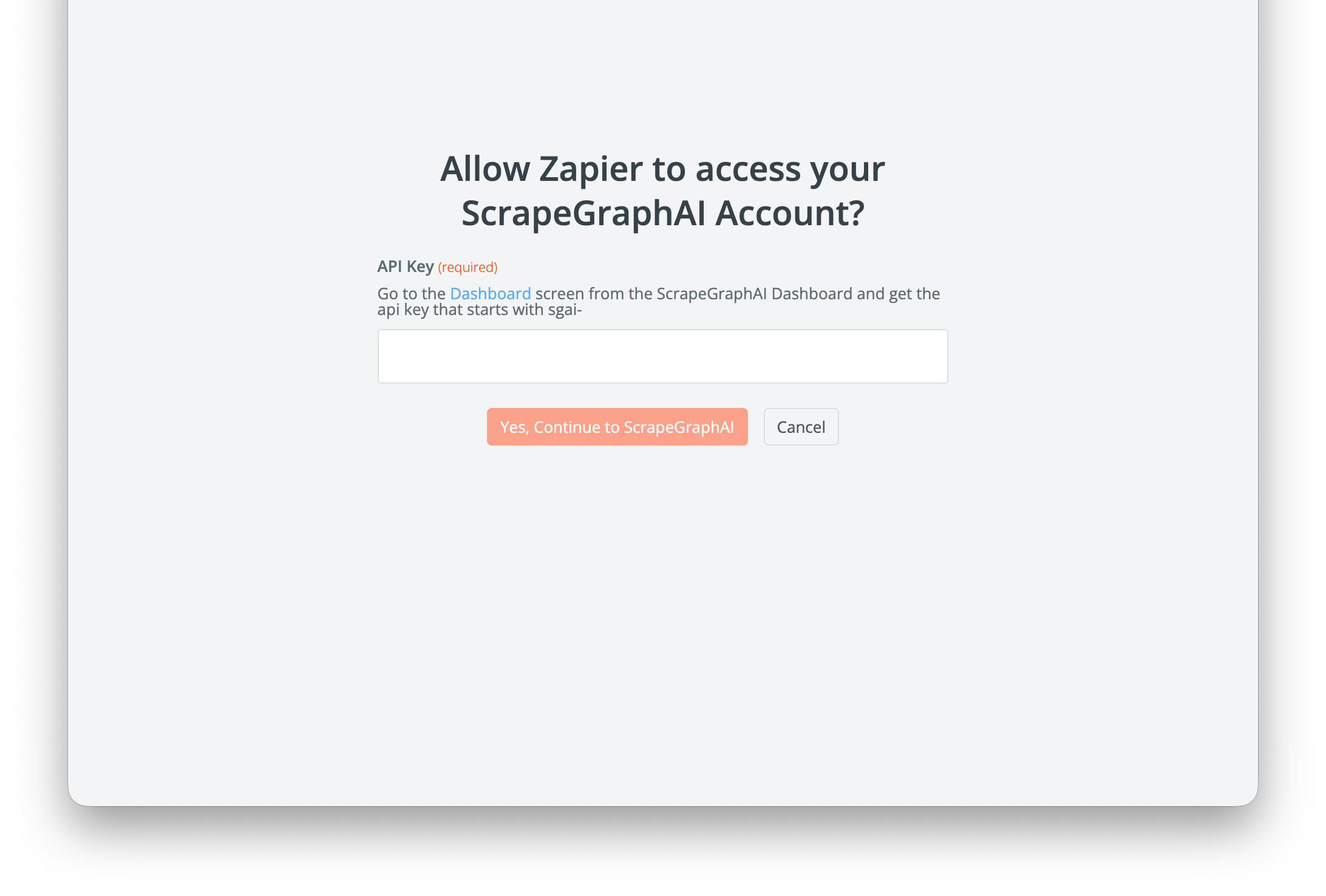
When prompted, click Sign in → paste your SGAI-APIKEY from the dashboard.
Save the connection — Zapier reuses it across every ScrapeGraphAI step in every Zap.
Your API key is stored on Zapier’s side and is sent in the SGAI-APIKEY header on each call. Rotate it from the dashboard and update the connection if needed.
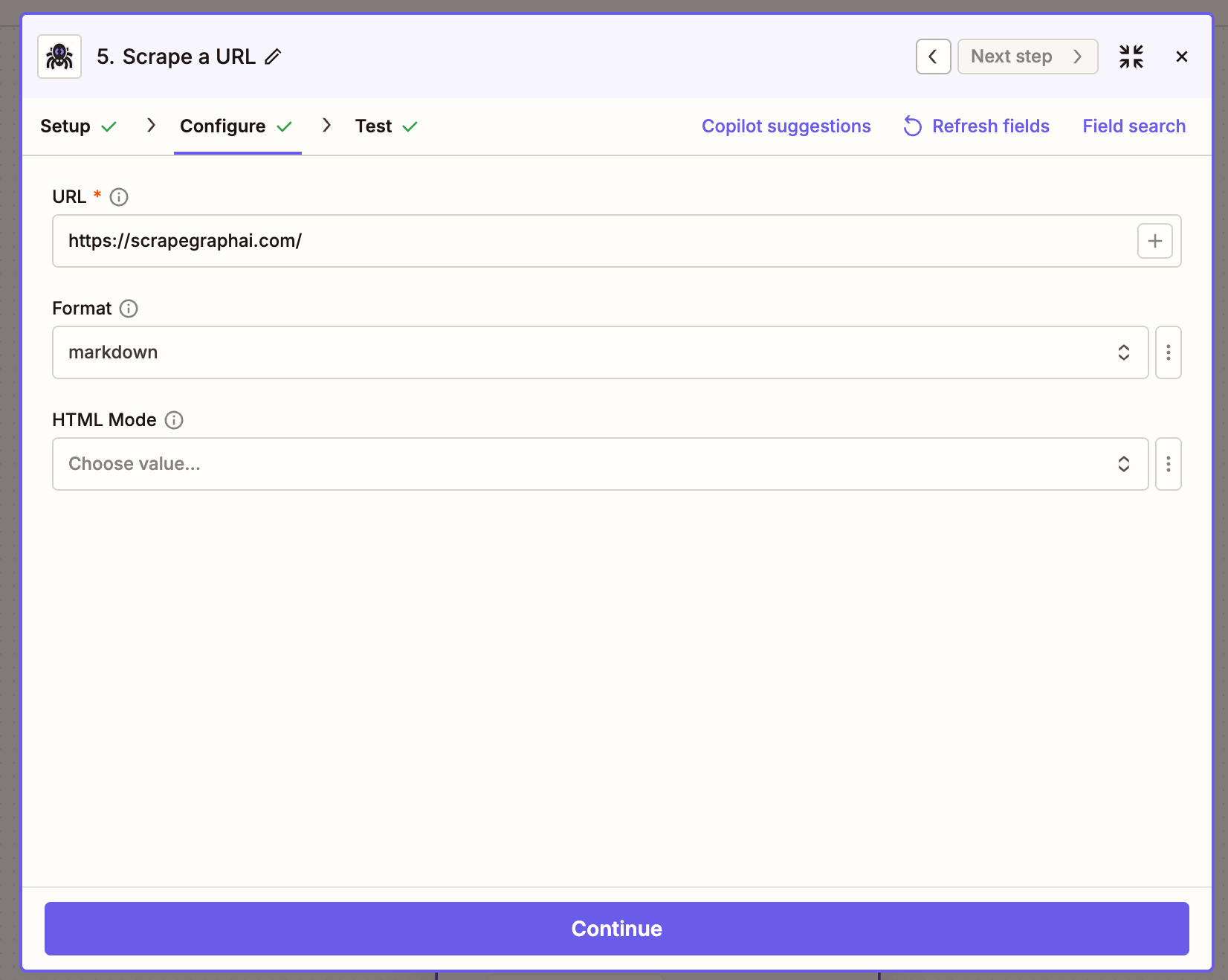
Fetch a page in markdown or HTML — single round-trip
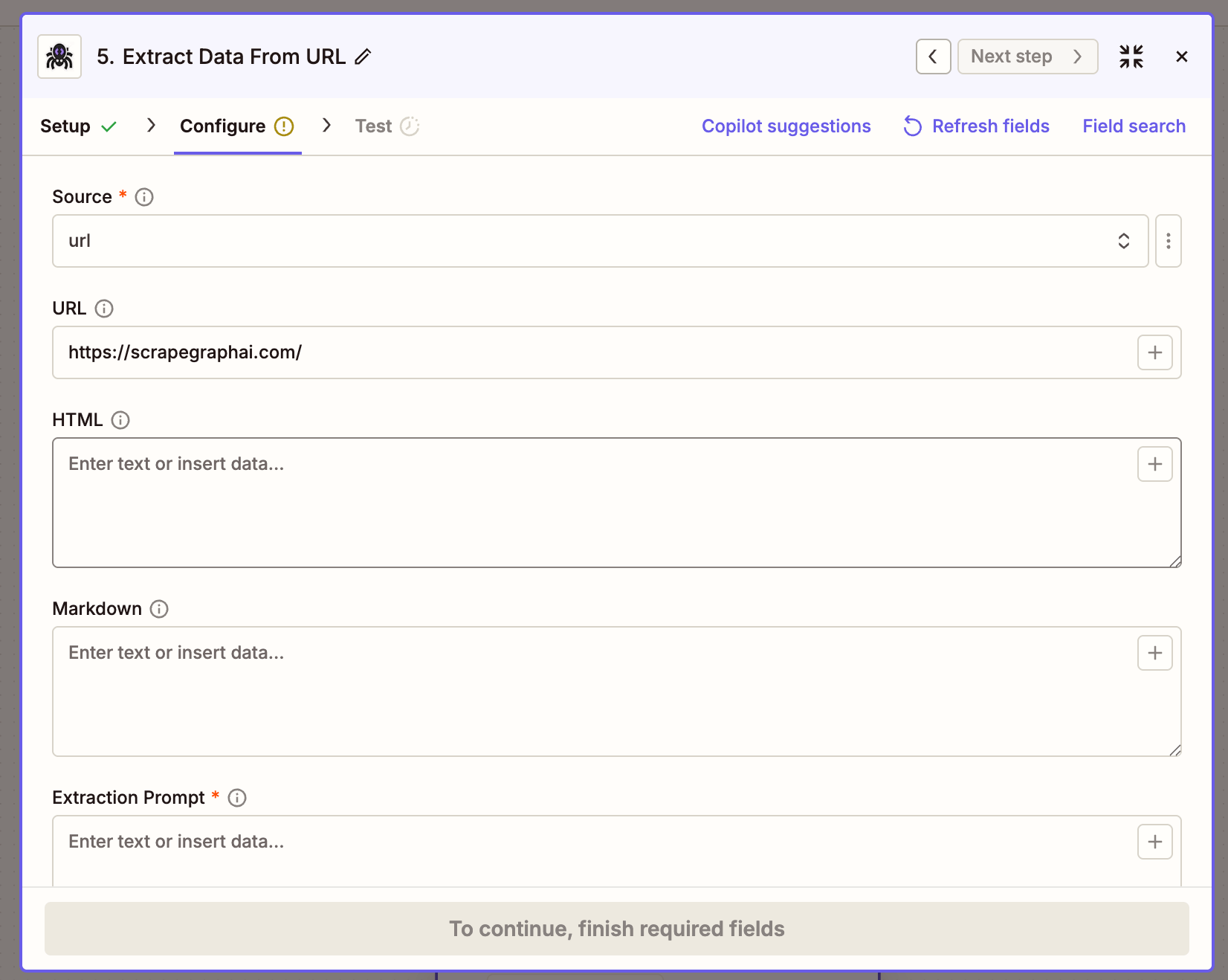
Extract Data From URL
Run a natural-language prompt over a URL, raw HTML, or markdown — optional JSON schema
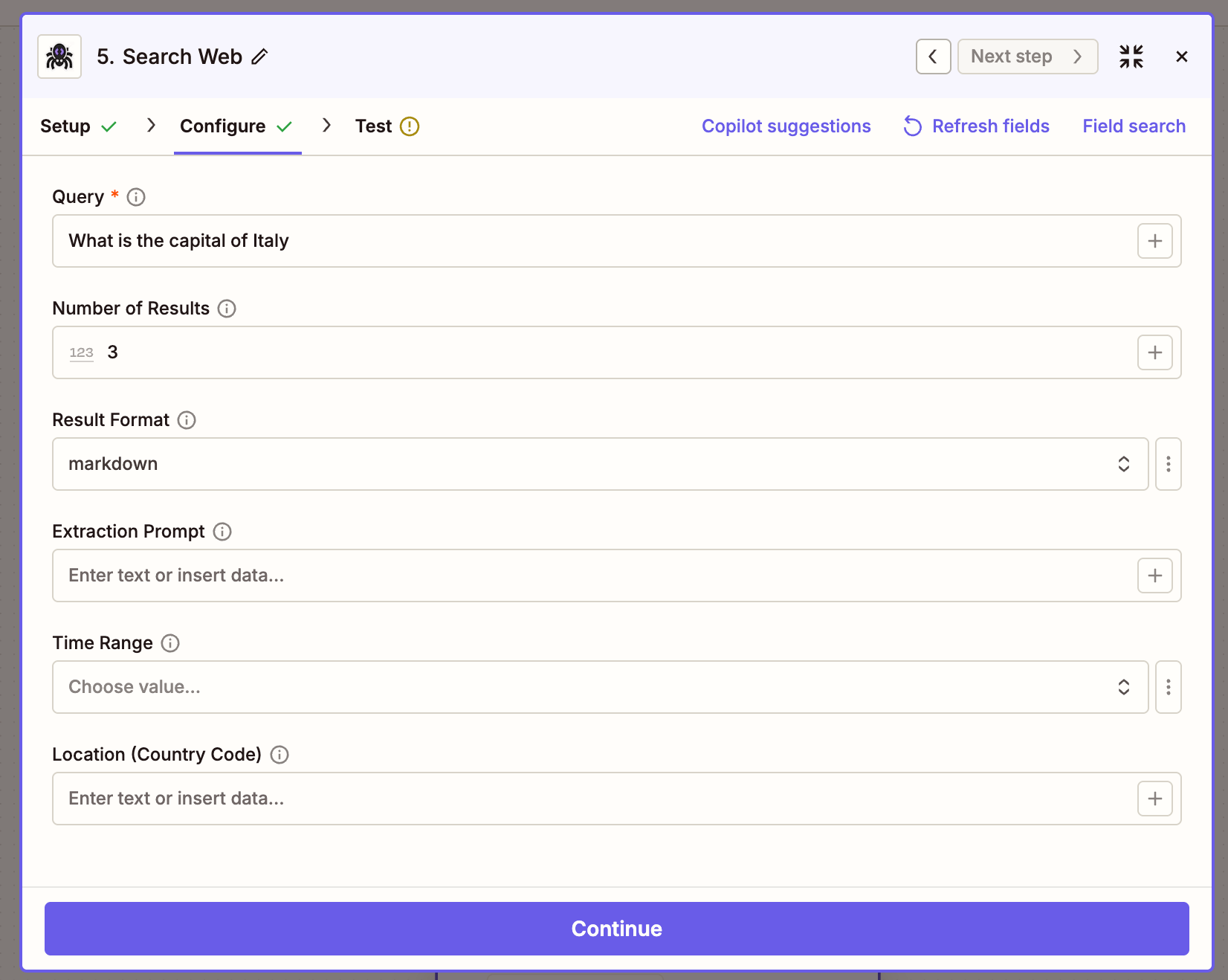
Search Web
AI web search with inline content; optional rollup prompt across results
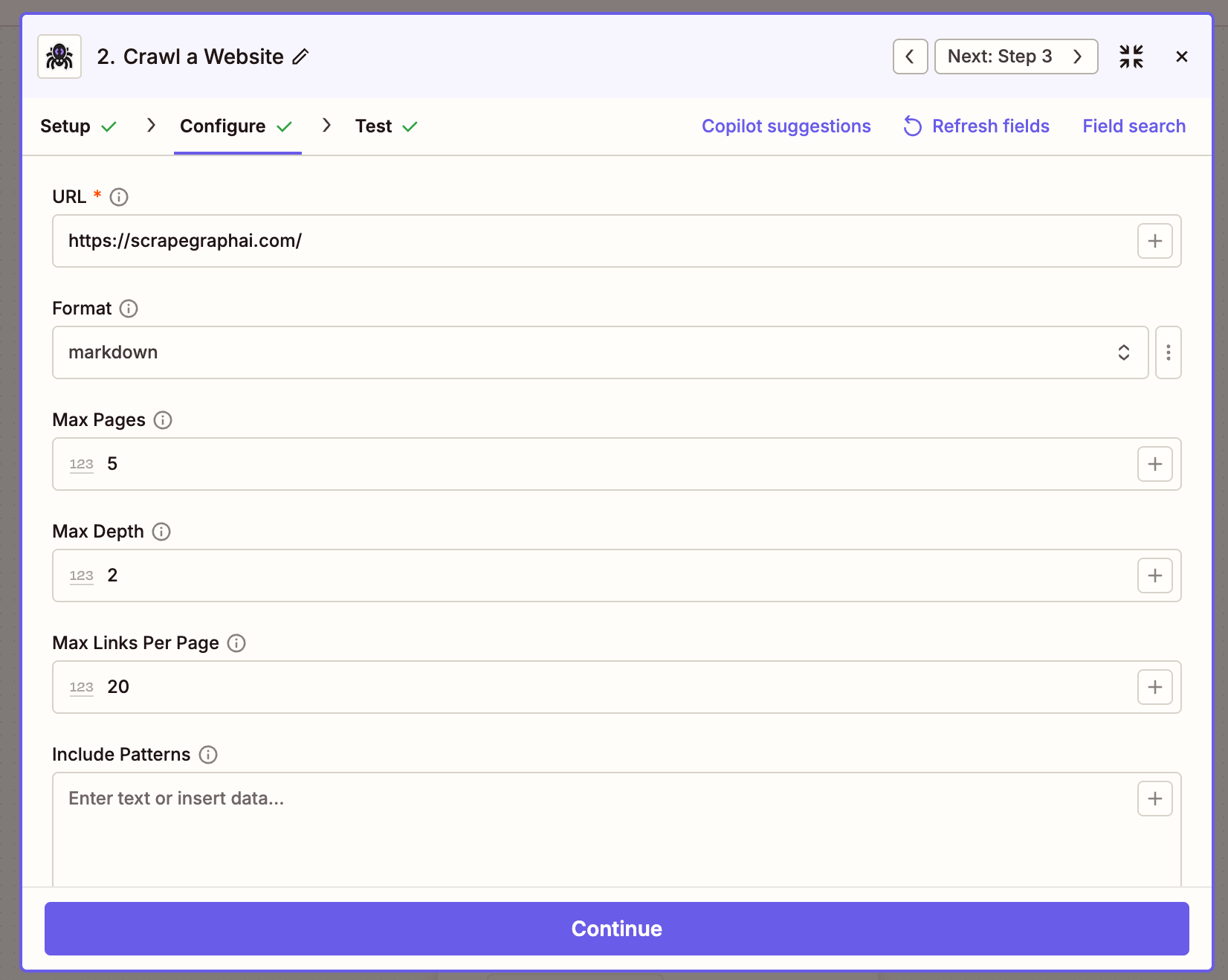
Crawl a Website
Start an async multi-page crawl from an entry URL — returns a job ID
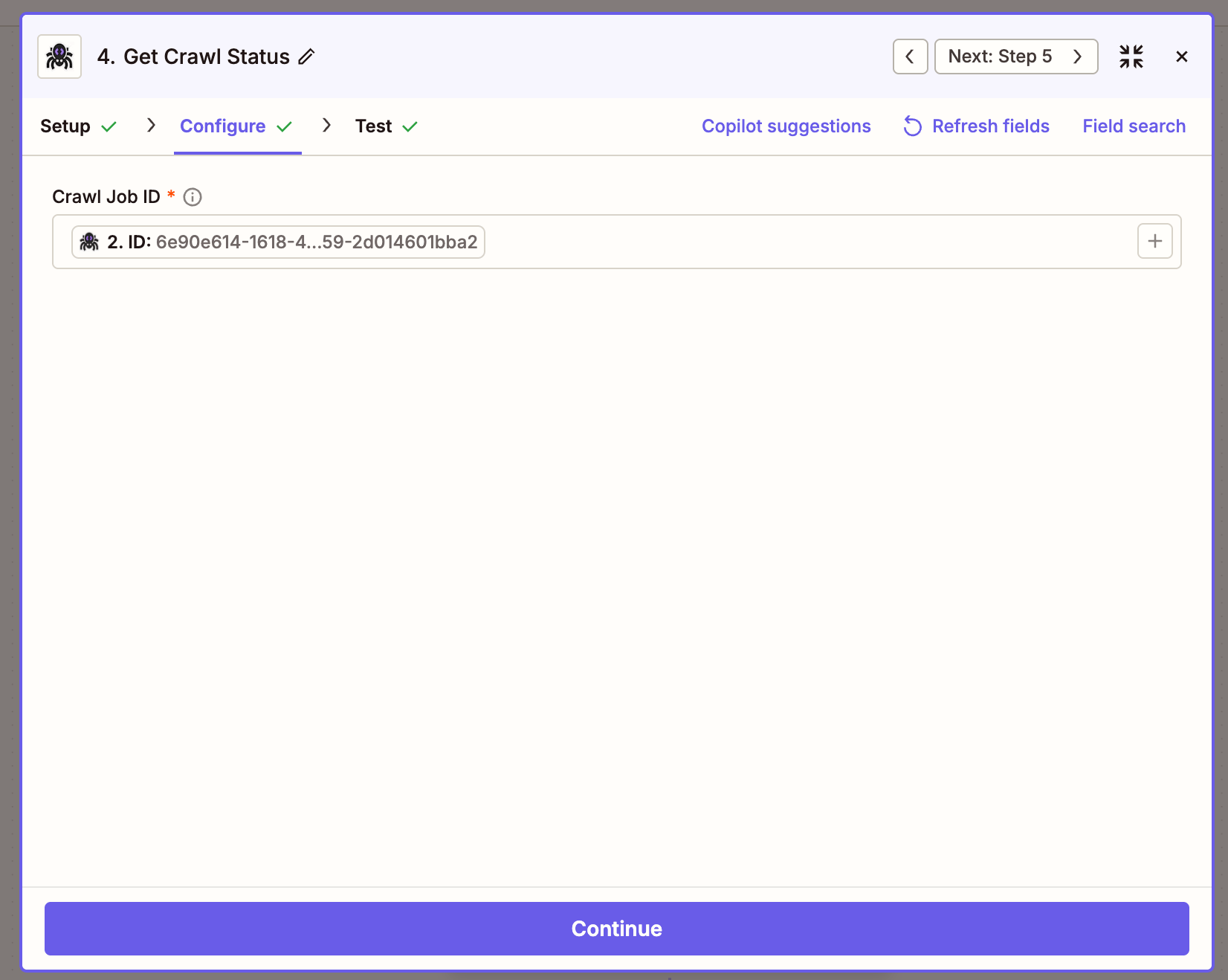
Get Crawl Status
Poll a crawl job by ID until it returns the pages array
Get a Past Result
Fetch any stored job result by id or scrapeRefId
Create Monitor
Schedule a recurring fetch on a cron with diff detection and optional webhook
Get Monitor Activity
Read recent ticks from a monitor (changed, diffs, status, createdAt)
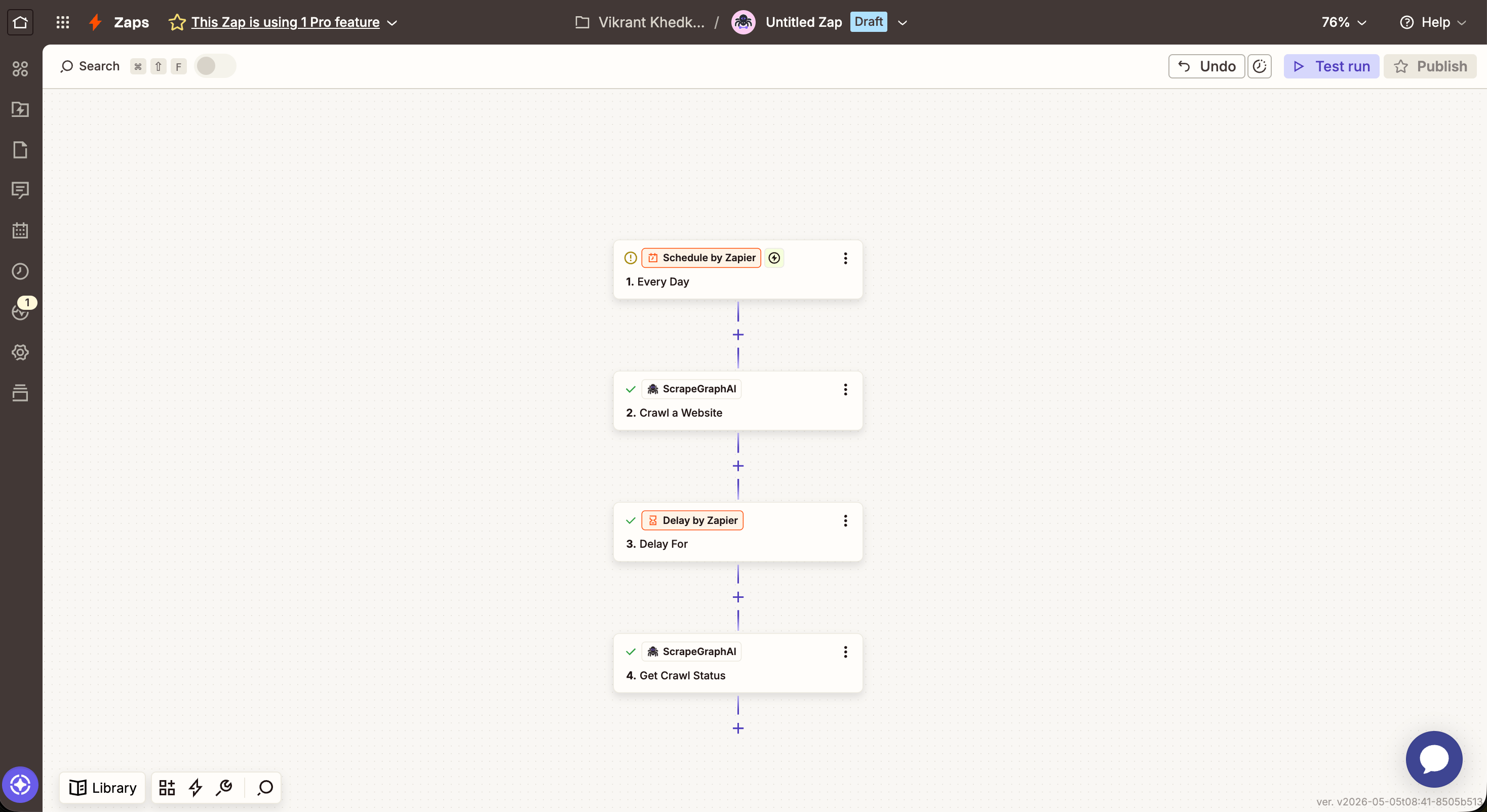
Zapier action timeouts cap individual steps at 30–60 seconds (depending on your plan). For larger crawls, use Crawl a Website to start the job, then a Delay + Get Crawl Status to poll — same async pattern as n8n.
Poll a crawl job until it completes. When status is completed, the response carries a pages array with a scrapeRefId per page that you can pass to Get a Past Result.
Field
Description
Crawl ID
The id returned by Crawl a Website — usually mapped from the previous step
The async pattern looks like this on the canvas — kick off the crawl, wait, then poll:
Action times out on Crawl a Website — large crawls run longer than Zapier’s per-action limit. Keep Crawl a Website as the start step, then add a Delay + Get Crawl Status to poll until status is completed.
Extract returns an empty json — sharpen the prompt, or pin the shape with a JSON Schema. Pages that need rendering may need Mode: JS.
Connection test fails — confirm the API key is from the v2 dashboard (scrapegraphai.com/dashboard). v1 keys won’t validate against the v2 API.
Get Past Result returns stale data — scrapeRefId always points to the latest stored result for that pointer. Trigger a fresh crawl to refresh.