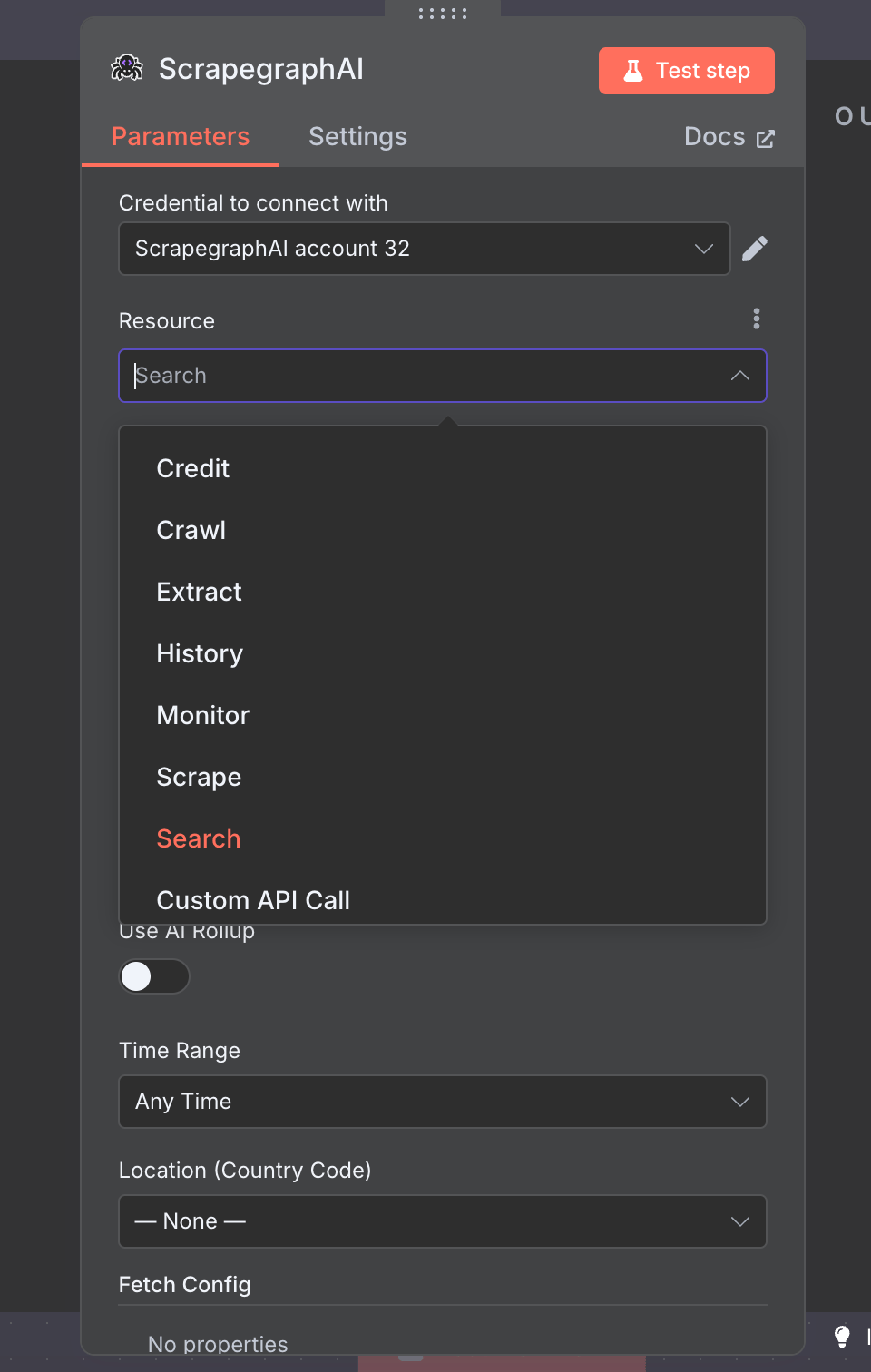
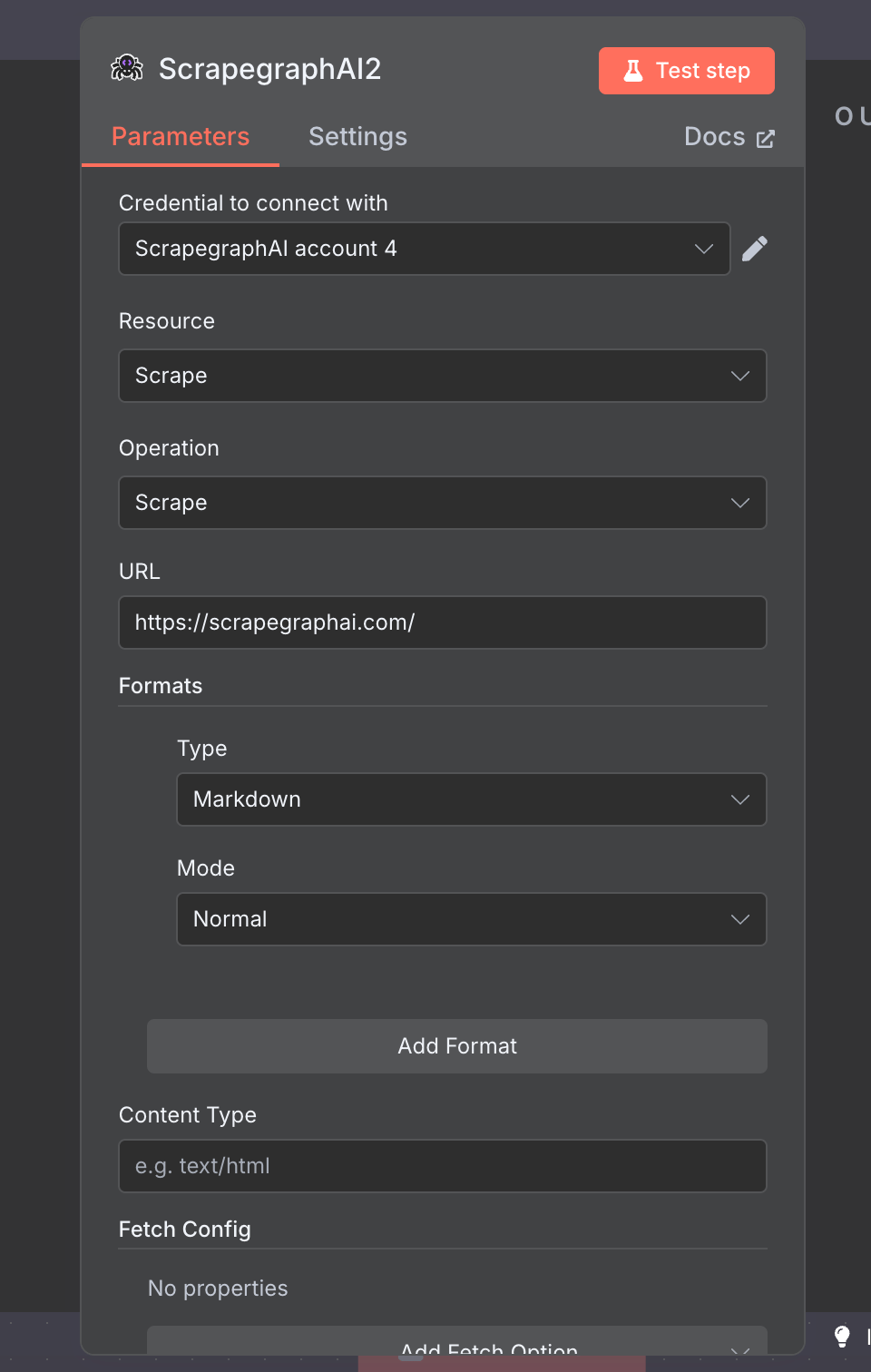
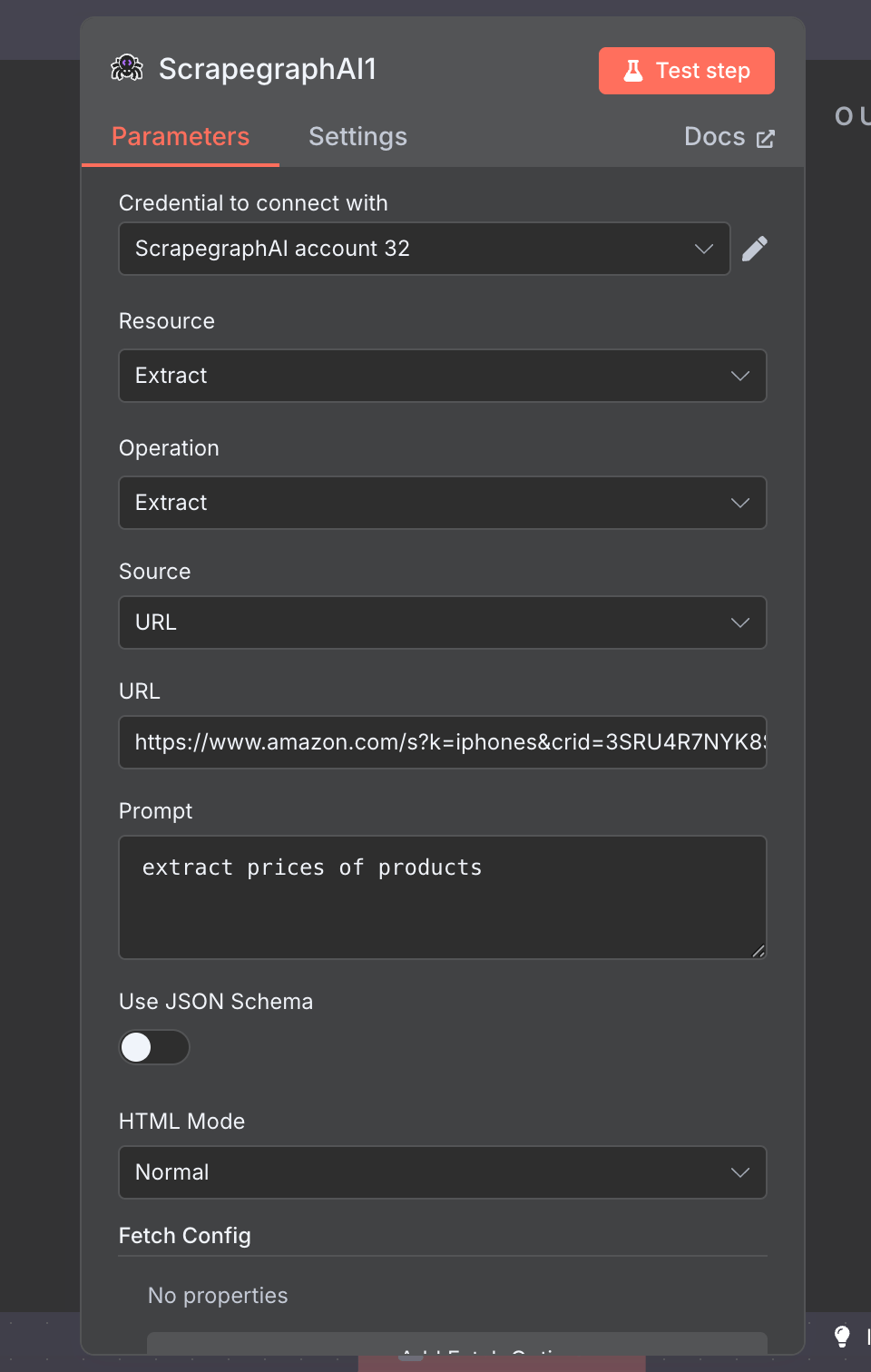
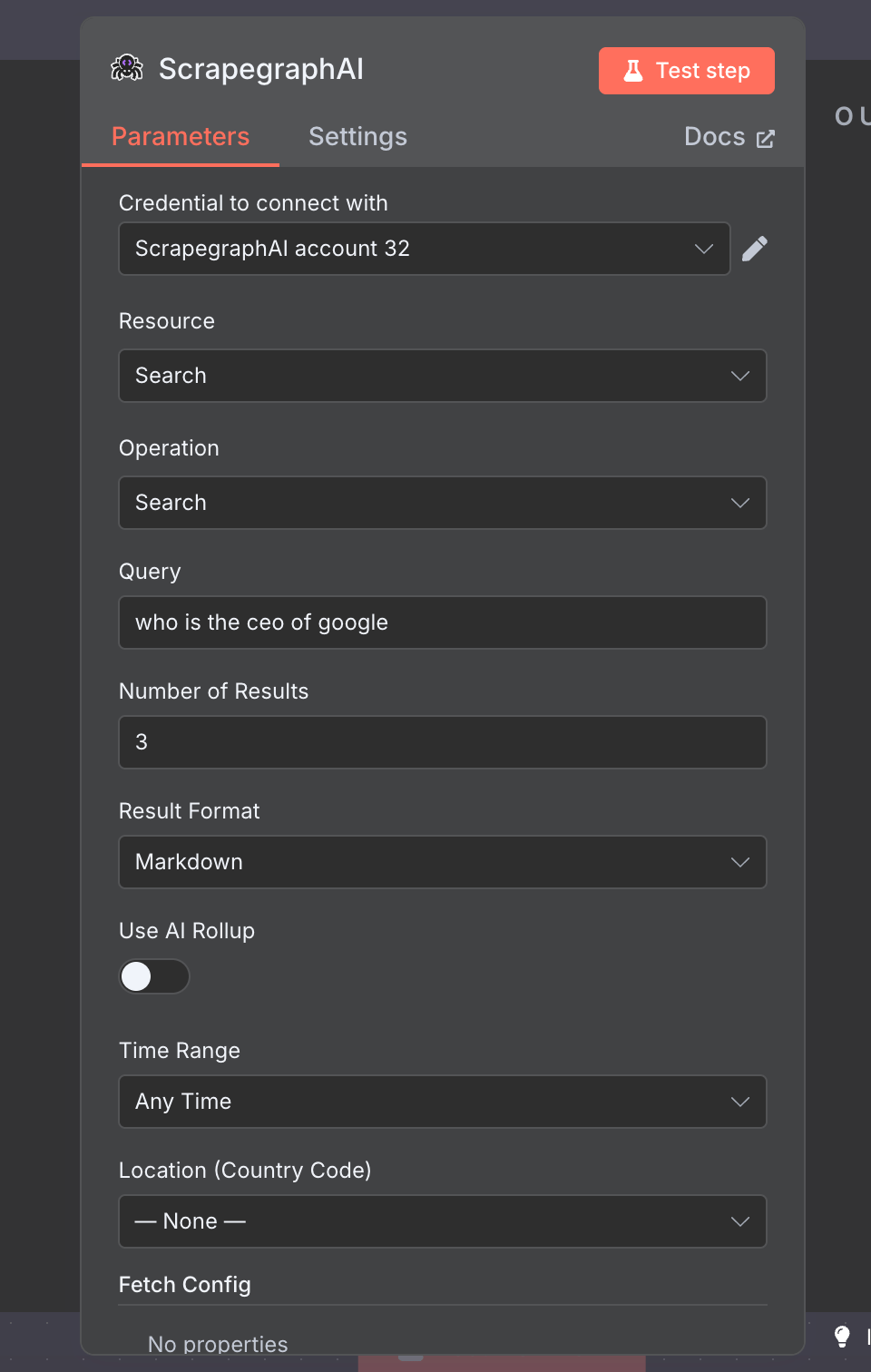
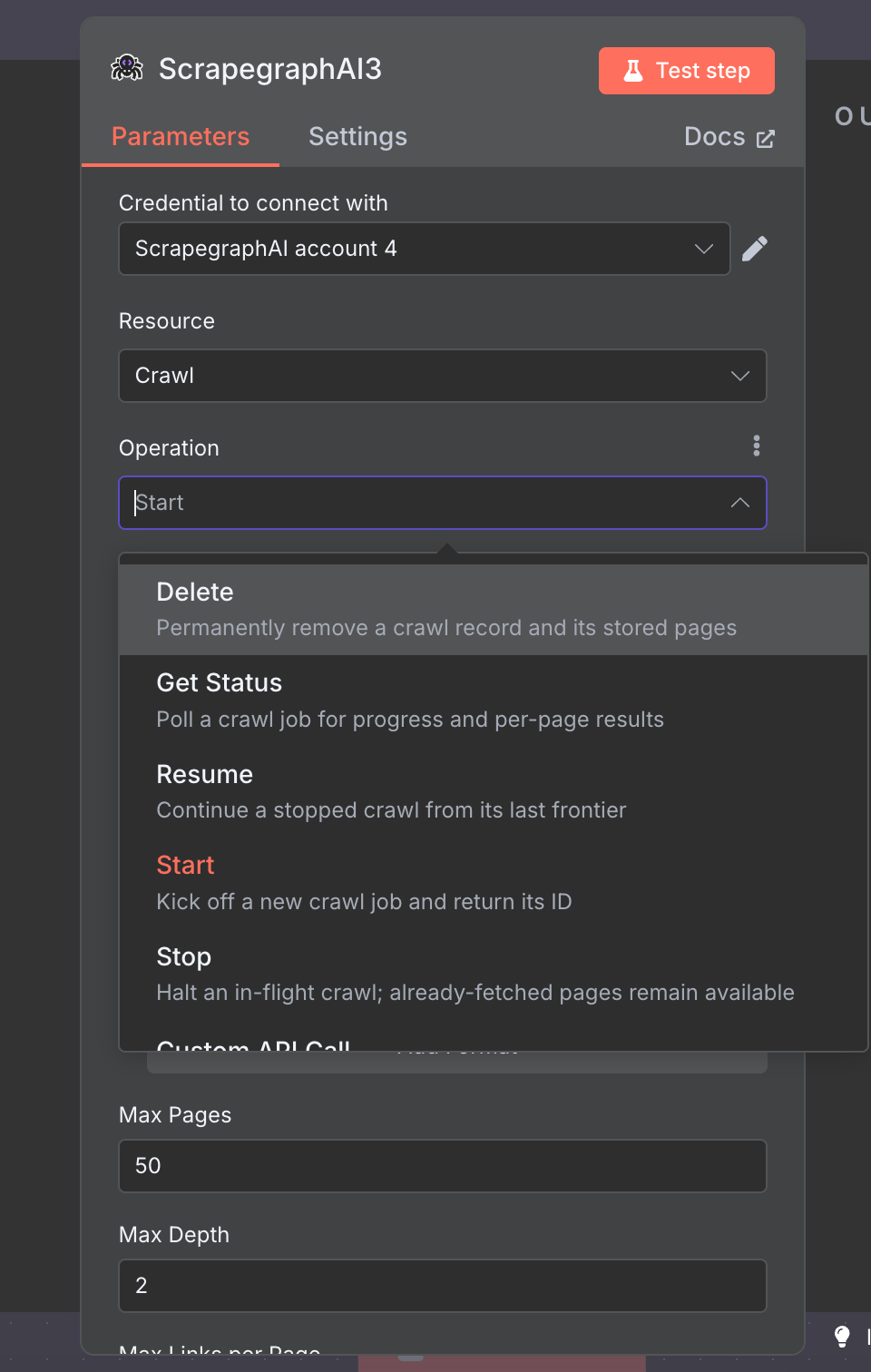
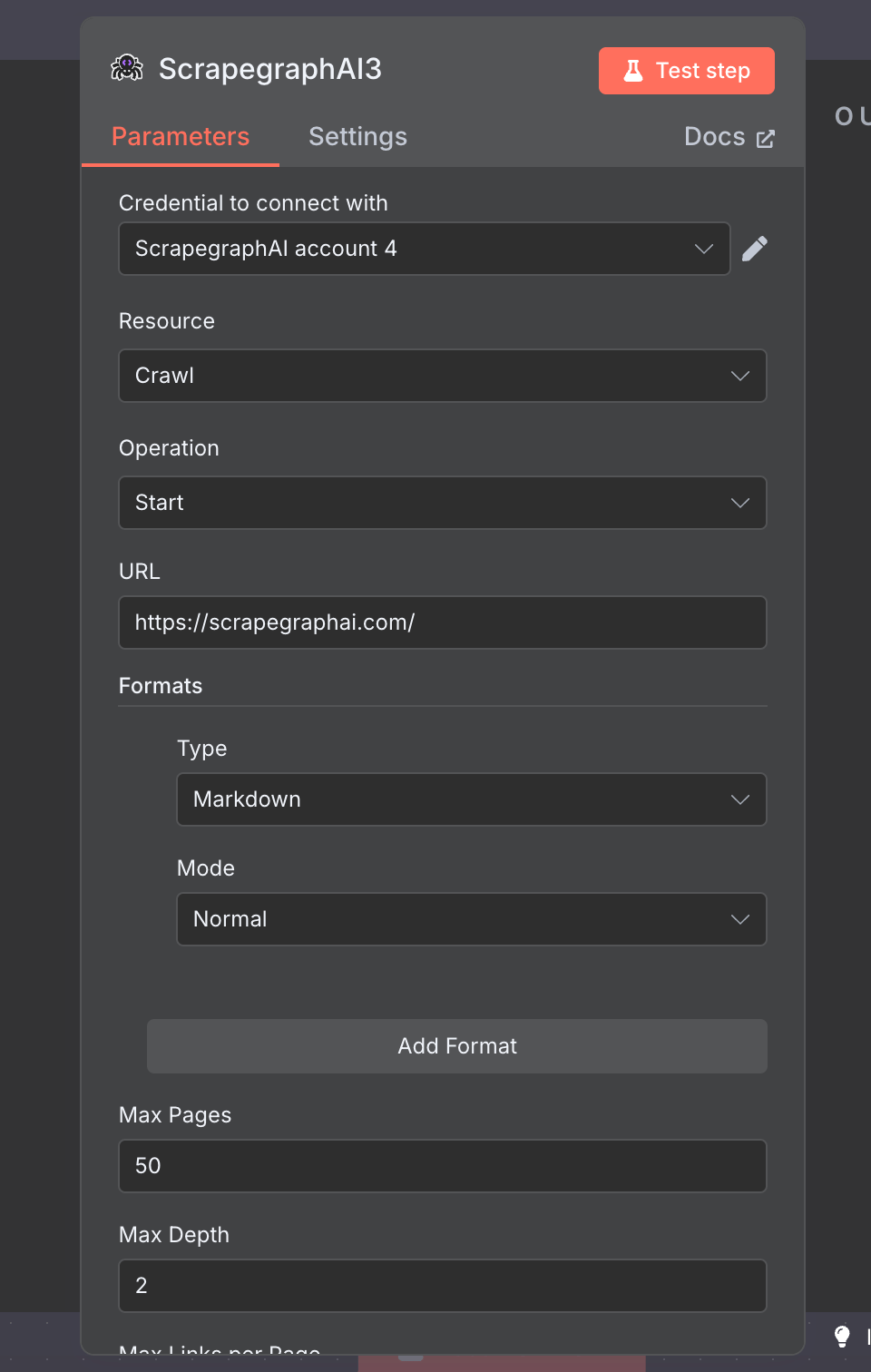
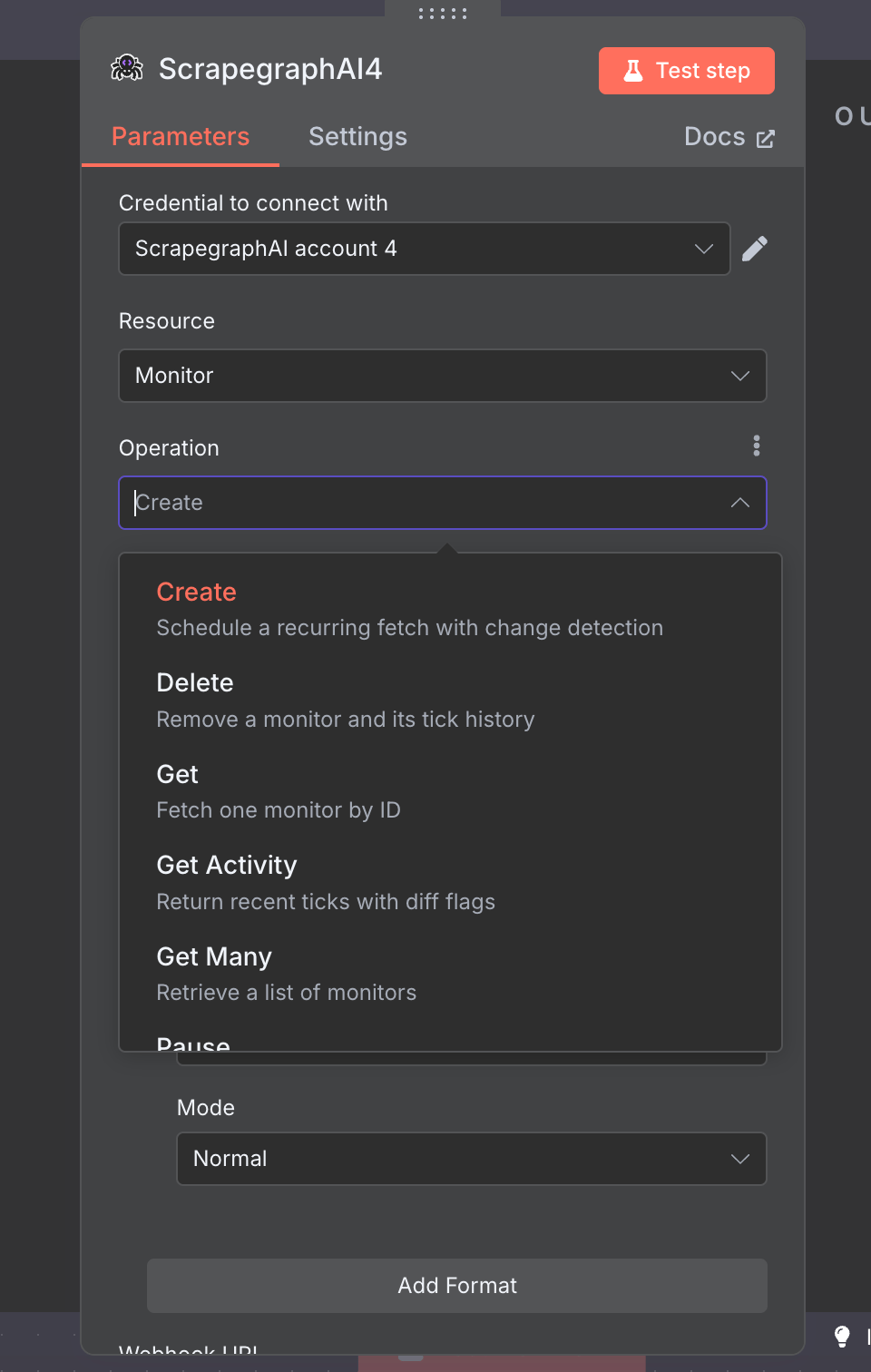
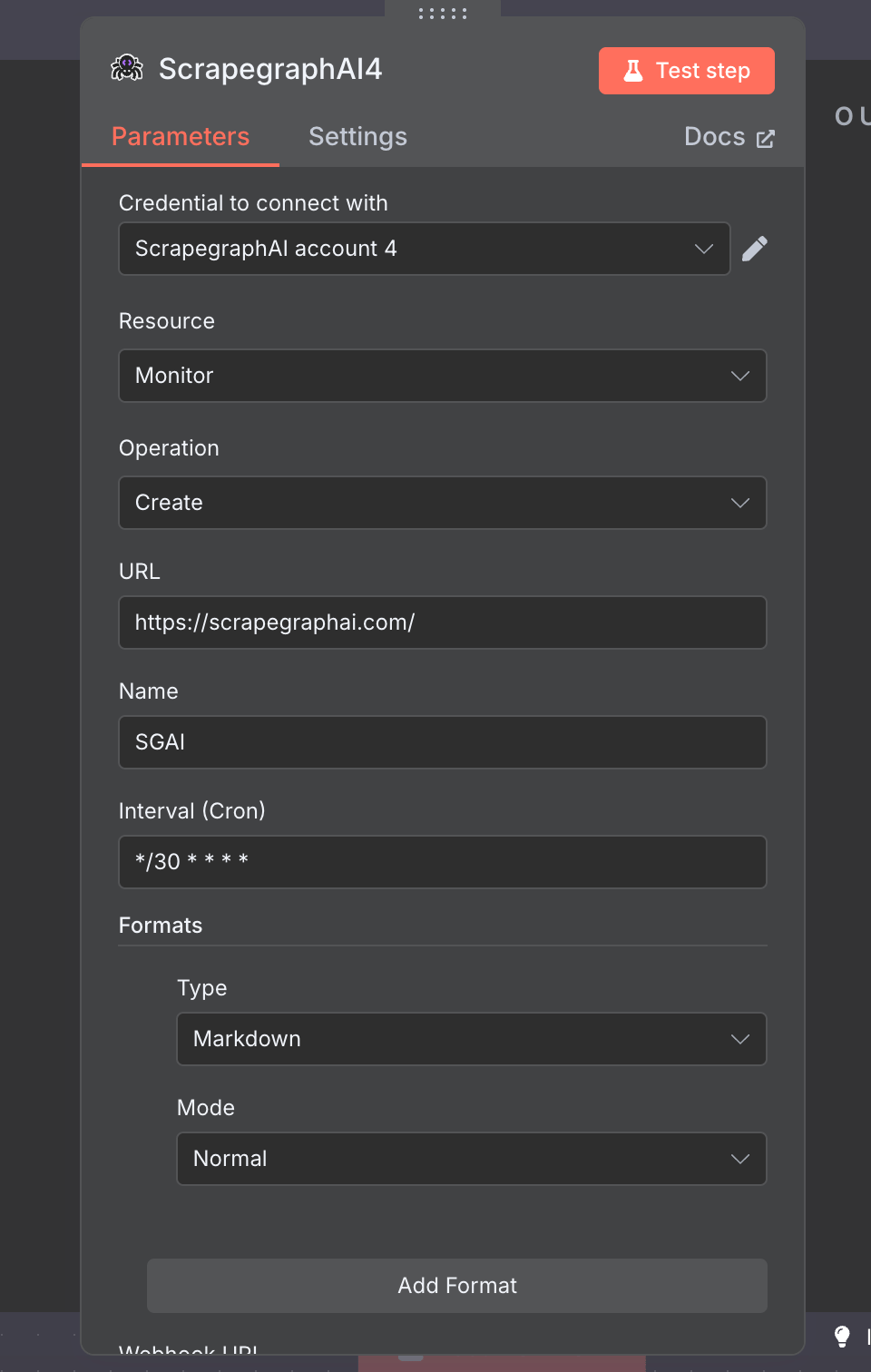
The official n8n-nodes-scrapegraphai community node exposes the full v2 API as a single node with seven resources: Scrape, Extract, Search, Crawl, Monitor, History, and Credit. Drop it into any n8n workflow, point it at a URL, and you get markdown, structured JSON, screenshots, or a recurring monitor — wired into the rest of your stack via the 400+ nodes n8n already ships with.
Cron-scheduled fetches with diff detection and webhooks
History
get, list
Look up past results by scrapeRefId — used to fetch full content for crawled pages
Credit
get
Check remaining credits and plan
Every content-producing operation (Scrape / Extract / Search) exposes an Output parameter with three modes — Simplified, Raw, or Selected Fields — so the response shape stays predictable when chained into AI Agent tools or downstream nodes.
Fetch a page in one or more formats — markdown, HTML, JSON (AI extraction), screenshot, links, summary, or branding. Add as many Format rows as you need; each one carries its own per-format options.
Field
Notes
URL
The page to fetch
Formats
Add one row per output format. Each format exposes its own sub-options (Mode for markdown/HTML, Prompt+Schema for JSON, Full Page/Width/Height/Quality for screenshots).
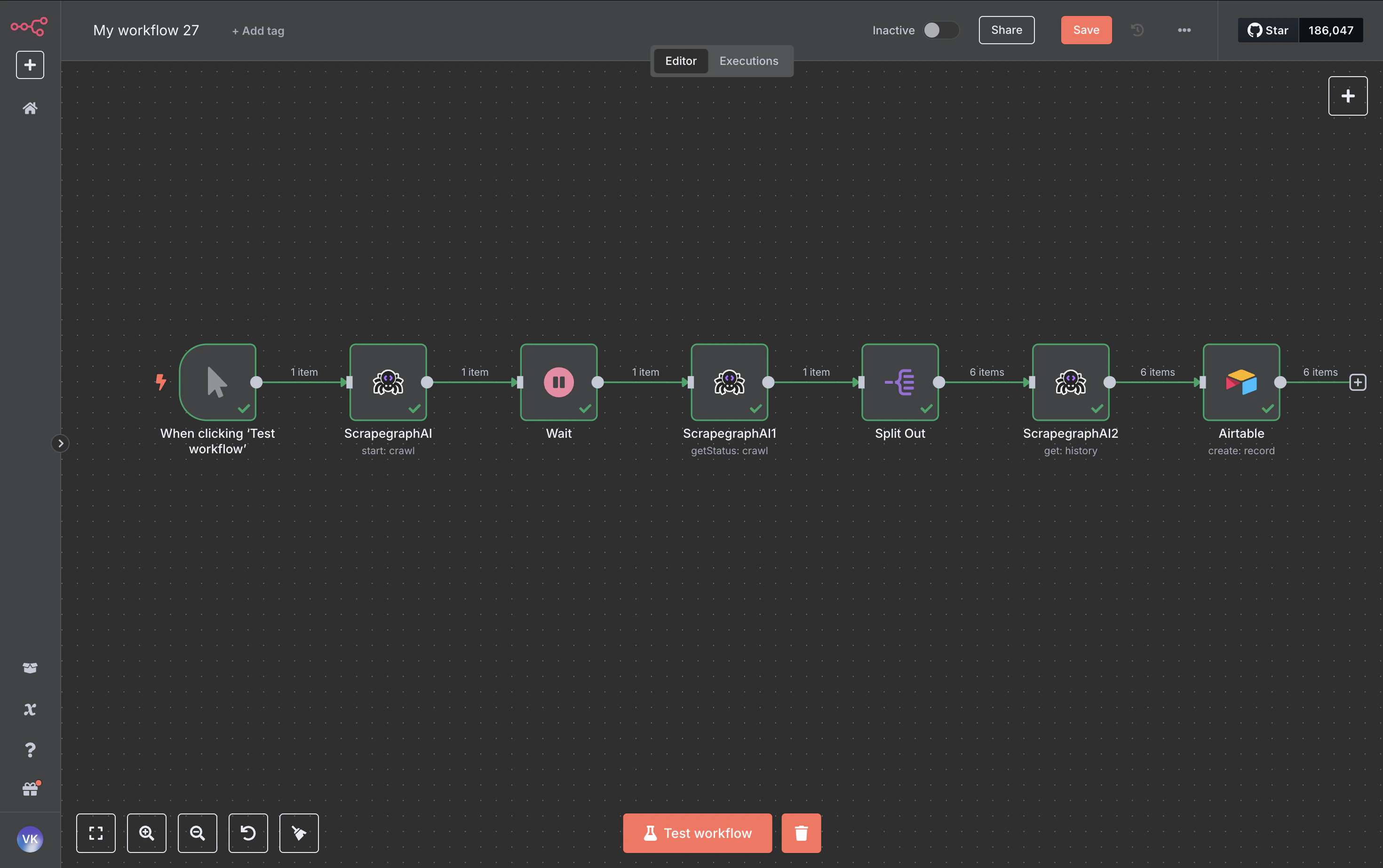
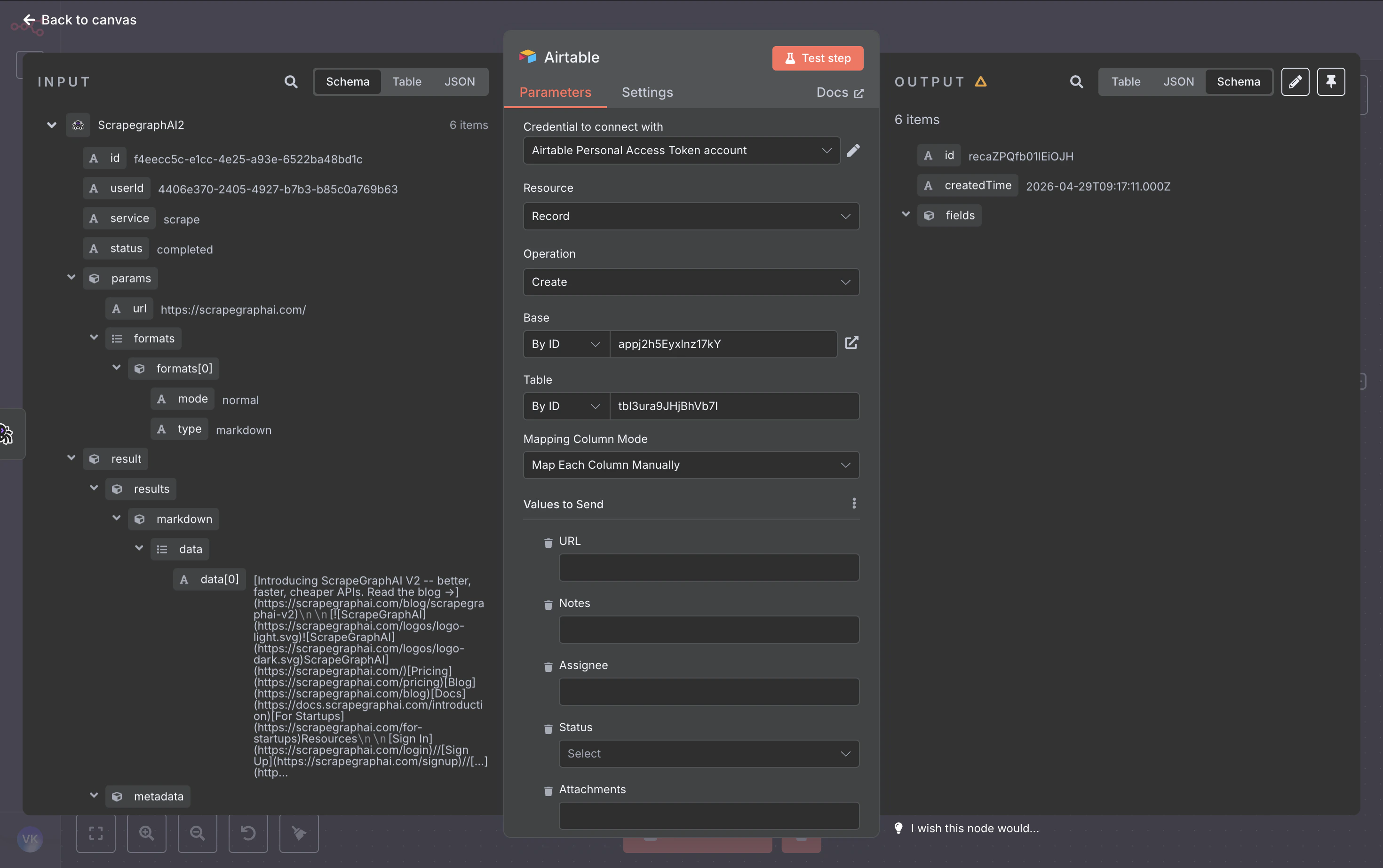
Example workflow: crawl a site, save every page to Airtable
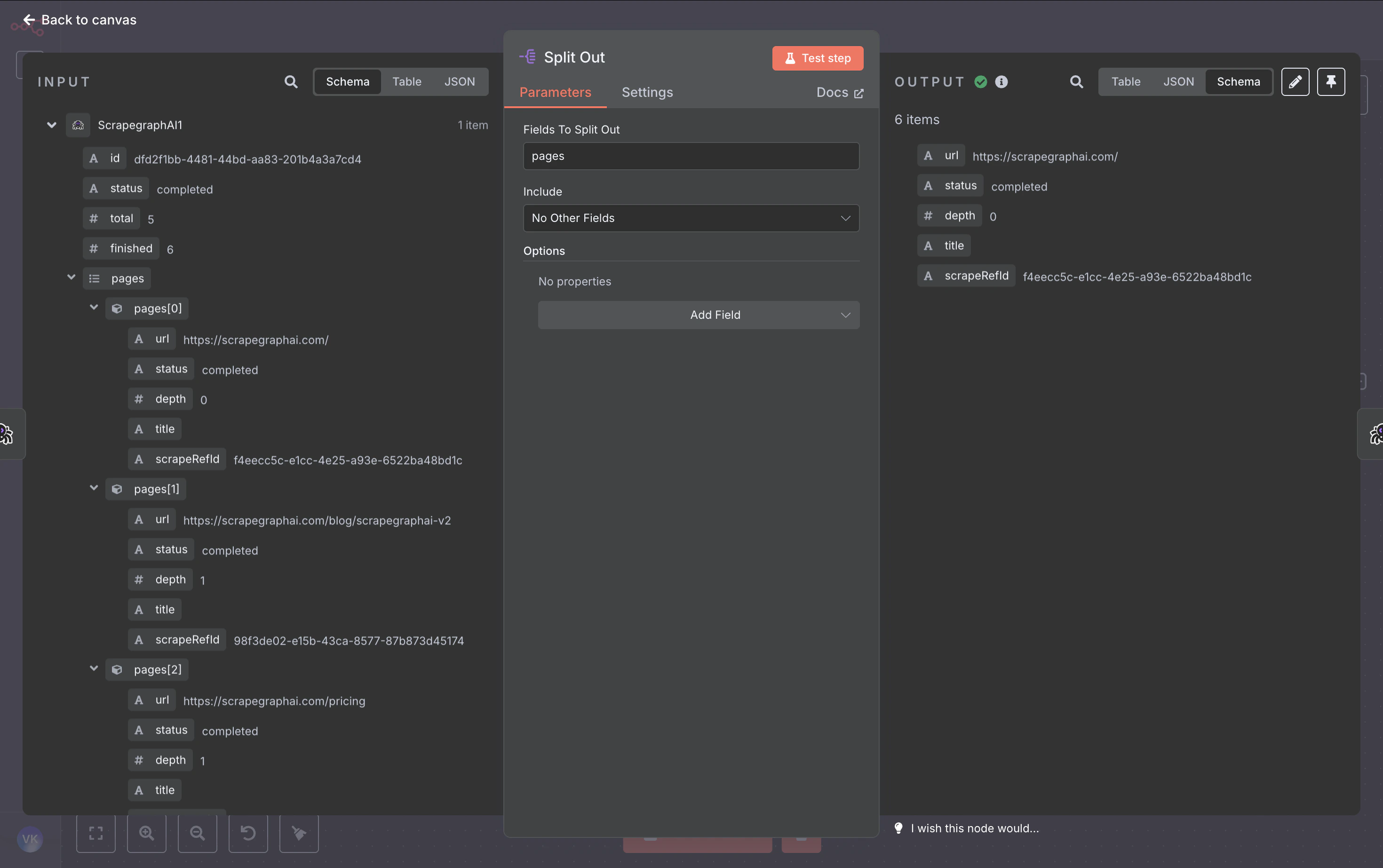
End-to-end walkthrough that chains Crawl → Wait → Crawl Status → Split Out → History → Airtable. The same pattern works for Notion, Google Sheets, Postgres, S3 — anywhere n8n can write.
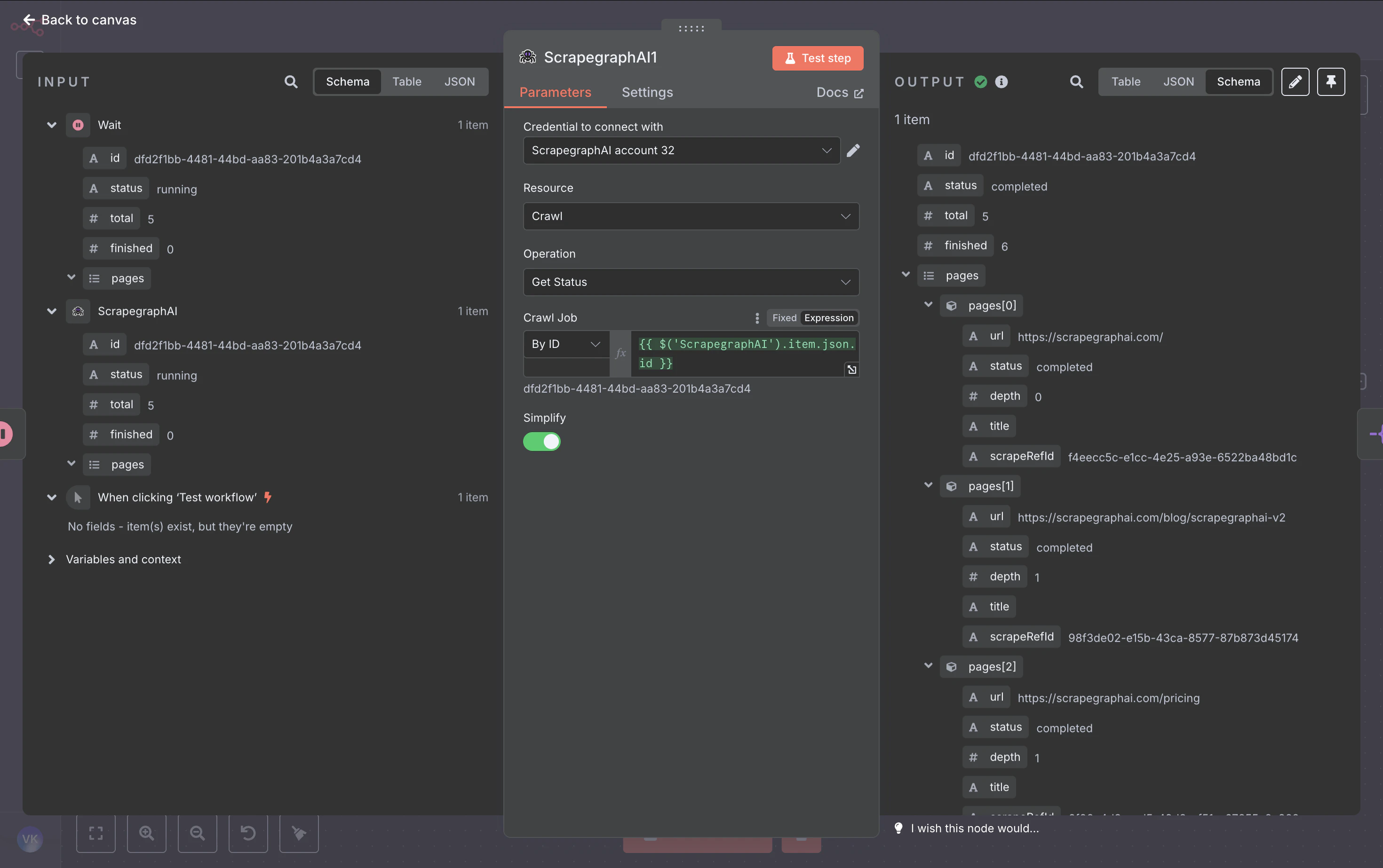
Pull the job state. When status is completed (or partial), the response includes a pages array with one entry per crawled page — each carrying the page URL, depth, title, and a scrapeRefId pointer to the stored result.
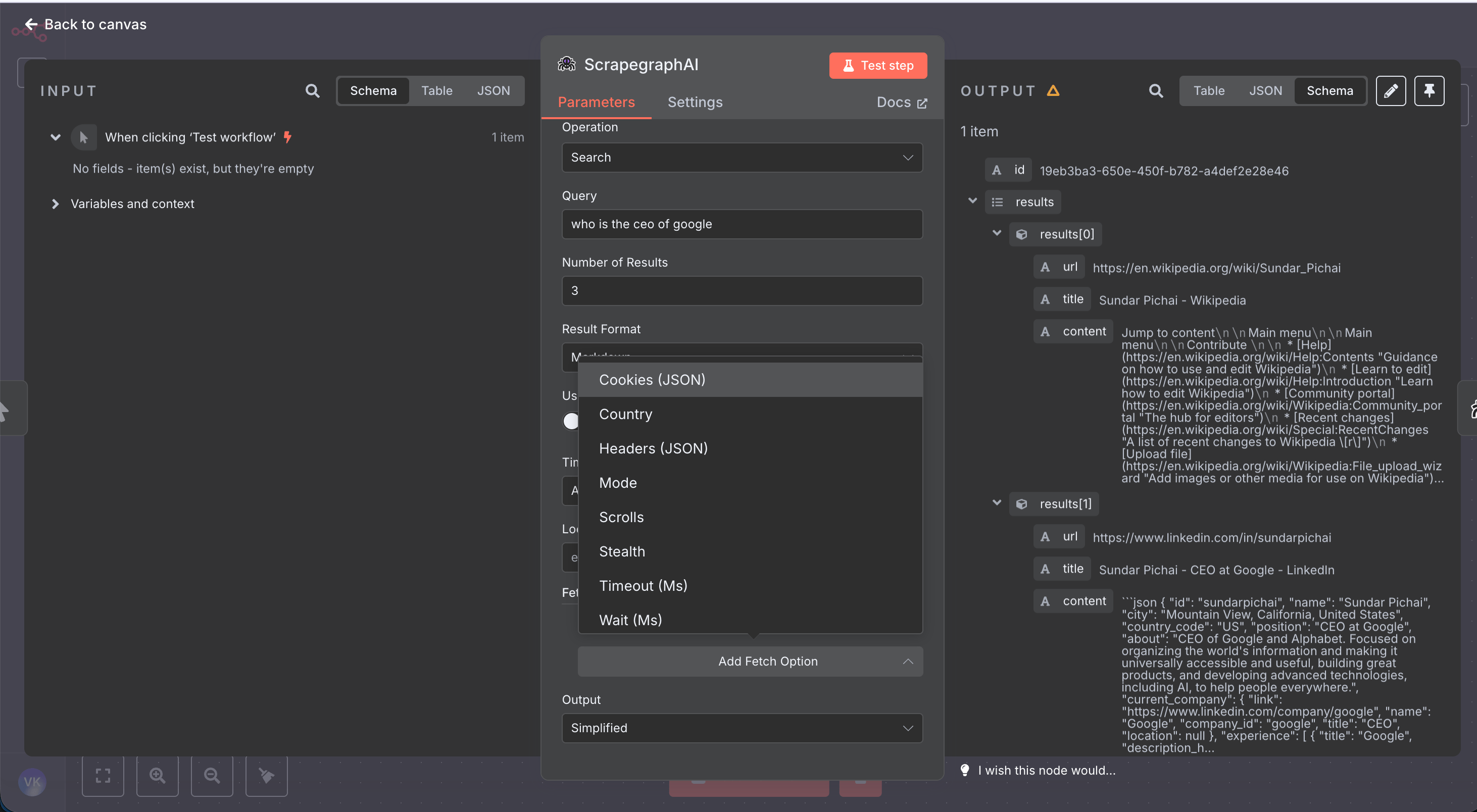
Five resources — Scrape, Extract, Search, Crawl, and Monitor — expose an optional Fetch Config collection that controls how each page is fetched. Open the dropdown on any of those operations to surface the eight knobs:
Field
Description
Mode
Fetch mode — Auto (default), Fast (skips JS rendering), or JS (executes scripts)
Stealth
Residential proxy + anti-bot headers. Adds 5 credits per call
Country
Two-letter ISO country code for geo-targeted proxy (e.g. us, de, jp)
Wait (Ms)
Milliseconds to wait after page load (0–30000)
Timeout (Ms)
Request timeout in milliseconds (1000–60000)
Scrolls
Number of page scrolls to trigger lazy-loaded content (0–100)
Headers (JSON)
Custom HTTP headers as a JSON object string
Cookies (JSON)
Cookies as a JSON object string
Reach for Stealth + Mode = JS + Wait = 2000–5000 when a site blocks bots or only renders content after JavaScript runs. Combine with Country for region-locked pages.
Unknown field name: "id" from Airtable — your column names don’t match. Switch the Airtable node’s mapping to Map Each Column Manually and only fill the columns that exist in your table.
Crawl Get Status returns pages: [] — the crawl is still running. Increase the Wait duration or poll until status === "completed".
History Get returns an old result — scrapeRefId always points to the latest result for that pointer. Trigger a fresh crawl to refresh.
Credentials test fails — confirm the key is from the v2 dashboard. The node calls https://v2-api.scrapegraphai.com/api/credits; v1 keys won’t validate.