Documentation Index
Fetch the complete documentation index at: https://docs.scrapegraphai.com/llms.txt
Use this file to discover all available pages before exploring further.
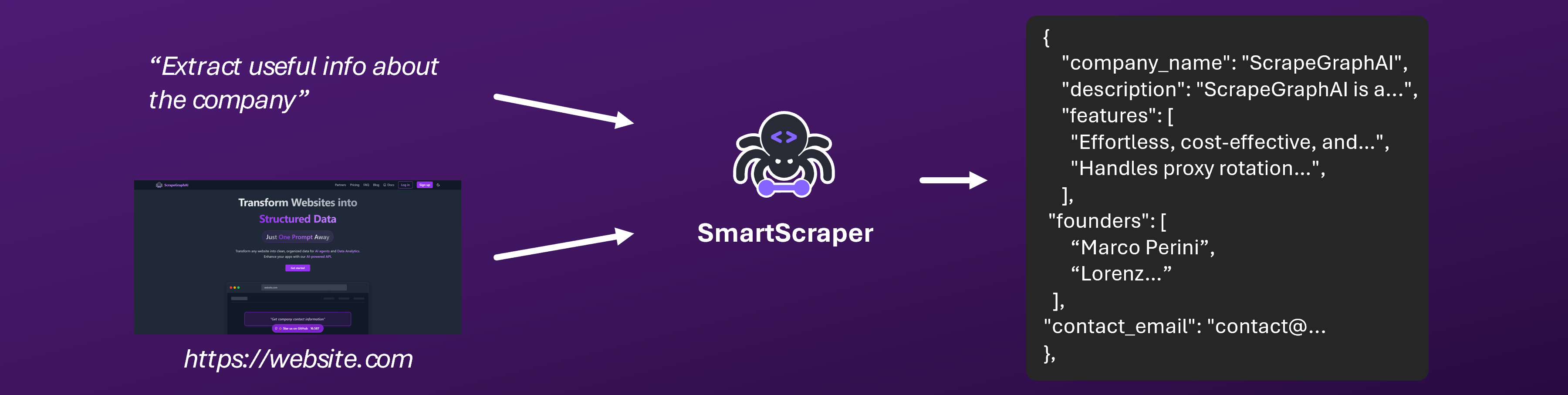
Overview
Thewait_ms parameter controls how many milliseconds the scraper waits before capturing page content. This is useful for pages that load content dynamically after the initial page load, such as:
- Single Page Applications (SPAs)
- Pages with lazy-loaded content
- Websites that render content via client-side JavaScript
- Pages with animations or delayed content loading
Parameter Details
| Field | Value |
|---|---|
| Parameter | wait_ms |
| Type | Integer |
| Required | No |
| Default | 3000 (3 seconds) |
| Validation | Must be a positive integer |
Supported Services
Thewait_ms parameter is available on the following endpoints:
- SmartScraper - AI-powered structured data extraction
- Scrape - Raw HTML content extraction
- Markdownify - Web content to markdown conversion
Usage Examples
Python SDK
JavaScript SDK
cURL
Async Python SDK
When to Adjust wait_ms
Increase wait time when:
- The target page loads content dynamically via JavaScript
- You’re scraping a SPA (React, Vue, Angular) that needs time to hydrate
- The page fetches data from APIs after initial load
- You’re seeing incomplete or empty results with the default wait time
Decrease wait time when:
- The target page is static HTML with no dynamic content
- You want faster scraping for simple pages
- You’re scraping many pages and want to optimize throughput
Best Practices
- Start with the default - The default value of 3000ms works well for most websites. Only adjust if you’re seeing incomplete results.
- Test incrementally - If the default doesn’t capture all content, try increasing in 1000ms increments (4000, 5000, etc.) rather than setting a very high value.
- Balance speed and completeness - Higher wait times ensure more content is captured but increase response time and resource usage.
Troubleshooting
Content still missing after increasing wait_ms
Content still missing after increasing wait_ms
If increasing
wait_ms doesn’t capture all content:- Check if the content requires user interaction (clicks, scrolls) - use
number_of_scrollsfor infinite scroll pages - Verify the content isn’t behind authentication - use custom headers/cookies
Scraping is too slow
Scraping is too slow
If scraping is taking longer than expected:
- Lower the
wait_msvalue for static pages - Use the default (omit the parameter) unless you specifically need a longer wait
- Consider using async clients for parallel scraping
API Reference
For detailed API documentation, see:Support & Resources
API Reference
Detailed API documentation
Dashboard
Monitor your API usage and credits
Community
Join our Discord community
GitHub
Check out our open-source projects
Need Help?
Contact our support team for assistance with wait time configuration or any other questions!