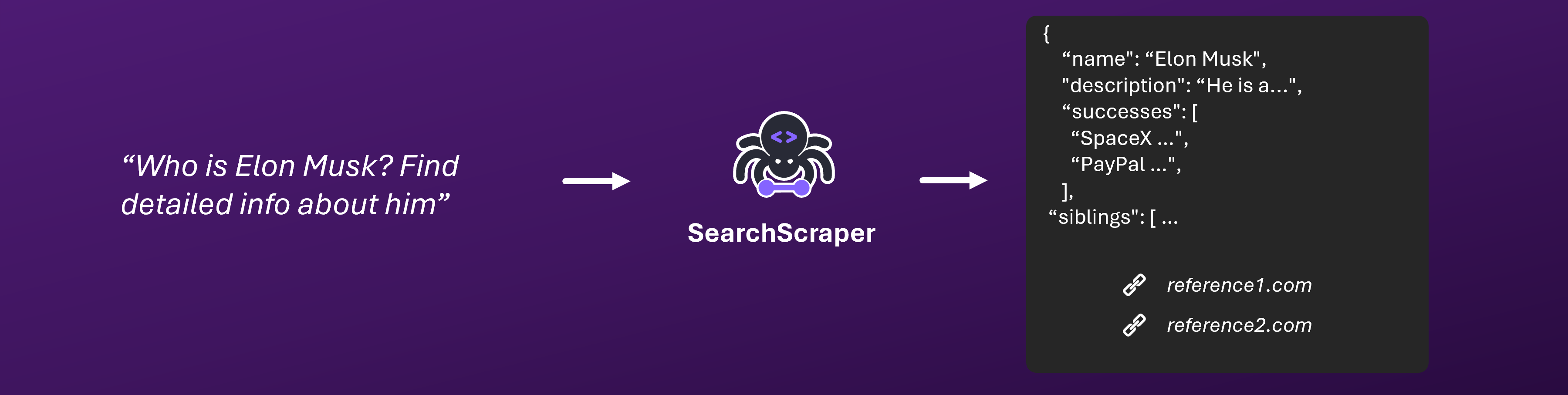
Overview
SearchScraper is our advanced LLM-powered search service that intelligently searches and aggregates information from multiple web sources. Using state-of-the-art language models, it understands your queries and extracts relevant information across the web, providing comprehensive answers with full source attribution. SearchScraper offers two modes:- AI Extraction Mode (default): Uses AI to extract and structure specific information (10 credits per page)
- Markdown Mode: Returns raw markdown content from scraped pages (2 credits per page)
Try SearchScraper instantly in our interactive playground
Getting Started
Quick Start
AI Extraction Mode (Default)
Markdown Mode (Cost-Effective)
Geo-Targeted Search
Filter search results to a specific geographic region using thelocation_geo_code parameter:
Geo-Targeting: Use standard country codes (e.g., “us” for United States, “gb” for United Kingdom, “de” for Germany) to filter search results to a specific region. This is useful for location-specific queries like local businesses, regional news, or country-specific information.
Time Range Filter
Filter search results by date range using thetime_range parameter:
Time Range Filtering: Use the time range filter to get only recent results. Available options:
past_hour- Results from the past hourpast_24_hours- Results from the past 24 hourspast_week- Results from the past weekpast_month- Results from the past monthpast_year- Results from the past year
Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| apiKey | string | Yes | The ScrapeGraph API Key. |
| user_prompt | string | Yes | A textual description of what you want to achieve. |
| num_results | number | No | Number of websites to search (3-20). Default: 3. Higher = deeper research. |
| extraction_mode | boolean | No | true = AI extraction mode (10 credits/page), false = markdown mode (2 credits/page). Default: true |
| output_schema | object | No | The Pydantic or Zod object that describes the structure and format of the response (AI extraction mode only) |
| location_geo_code | string | No | Geographic location code for geo-targeted search results (e.g., “us”, “gb”, “de”). Filters results to the specified region. |
| time_range | string | No | Date range filter for search results. Options: “past_hour”, “past_24_hours”, “past_week”, “past_month”, “past_year”. Filters results to the specified time period. |
| mock | boolean | No | Optional parameter to enable mock mode. When set to true, the request will return mock data instead of performing an actual search. Useful for testing and development. Default: false |
NEW: You can now control the number of websites to search (3-20) for deeper research. More sites = more credits. See advanced usage below!
Cost-Effective: Markdown mode uses only 2 credits per page compared to 10 credits for AI extraction mode, making it perfect for bulk content gathering and analysis.
Advanced: Website Limits & Credit Costs
Advanced: Website Limits & Credit Costs
You can now configure how many websites SearchScraper will search (from 3 up to 20). This allows you to balance research depth and credit usage.
- Default: 3 websites (30 credits AI mode / 6 credits markdown mode)
- Enhanced: 5 websites (50 credits AI mode / 10 credits markdown mode)
- Maximum: 20 websites (200 credits AI mode / 40 credits markdown mode)
- AI Extraction Mode: 30 credits base + 10 credits for each website above 3
- Markdown Mode: 6 credits base + 2 credits for each website above 3
- 3 websites: 30 credits (AI) / 6 credits (markdown)
- 5 websites: 50 credits (AI) / 10 credits (markdown)
- 10 websites: 100 credits (AI) / 20 credits (markdown)
- 20 websites: 200 credits (AI) / 40 credits (markdown)
num_results and extraction_mode in your request.Example Response
Example Response
request_id: Unique identifier for tracking your requeststatus: Current status of the search (“completed”, “running”, “failed”)result: The extracted data in structured JSON formatreference_urls: Source URLs for verificationerror: Error message (if any occurred during search)
Markdown Mode Response Example
Markdown Mode Response Example
When using markdown mode (Markdown Mode Response Fields:
extraction_mode: false), the response format is different:request_id: Unique identifier for tracking your requeststatus: Current status of the search (“completed”, “running”, “failed”)markdown_content: Raw markdown content from all scraped pages combinedreference_urls: Source URLs for verificationerror: Error message (if any occurred during search)
- No
resultfield (AI extraction not performed) markdown_contentcontains the raw markdown from scraped pages- Much faster and more cost-effective (2 credits per page vs 10 credits)
- Perfect for content analysis, bulk data gathering, or when you need the full page content
Key Features
Multi-Source Search
Intelligent search across multiple reliable web sources
AI Understanding
Advanced LLM models for accurate information extraction
Structured Output
Clean, structured data in your preferred format
Source Attribution
Full transparency with reference URLs
Use Cases
Research & Analysis
- Academic research and fact-finding
- Market research and competitive analysis
- Technology trend analysis
- Industry insights gathering
Data Aggregation
- Product research and comparison
- Company information compilation
- Price monitoring across sources
- Technology stack analysis
Content Creation
- Fact verification and citation
- Content research and inspiration
- Data-driven article writing
- Knowledge base building
Markdown Mode Use Cases
Markdown mode is perfect for scenarios where you need the full content of web pages rather than AI-extracted summaries:Content Analysis
- Analyze full article content for research
- Extract complete product descriptions
- Gather comprehensive documentation
- Build content databases
Bulk Data Collection
- Collect large amounts of text content
- Gather multiple pages for analysis
- Create content archives
- Build training datasets
Cost-Effective Scraping
- When you need full page content but want to minimize costs
- For high-volume content gathering
- When AI extraction isn’t needed
- For content that will be processed by your own AI models
Markdown Mode Complete Example
Markdown Mode Complete Example
Here’s a complete example of using markdown mode for content analysis:
Want to learn more about our AI-powered search technology? Visit our main website to discover how we’re revolutionizing web research.
Other Functionality
Retrieve a previous request
If you know the response id of a previous request you made, you can retrieve all the information.Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| apiKey | string | Yes | The ScrapeGraph API Key. |
| requestId | string | Yes | The request ID associated with the output of a previous searchScraper request. |
Custom Schema Example
Define exactly what data you want to extract using Pydantic or Zod:Advanced Schema Usage
The schema system in SearchScraper is a powerful way to ensure you get exactly the data structure you need. Here are some advanced techniques for using schemas effectively:Nested Schemas
You can create complex nested structures to capture hierarchical data:Schema Validation Rules
Enhance data quality by adding validation rules to your schema:Quality Improvement Tips
To get the highest quality results from SearchScraper, follow these best practices:1. Detailed Field Descriptions
Always provide clear, detailed descriptions for each field in your schema:2. Structured Prompts
Combine schemas with well-structured prompts for better results:3. Data Validation
Implement comprehensive validation to ensure data quality:4. Error Handling
Implement robust error handling for schema validation:Async Support
Example of using the async searchscraper functionality to search for information concurrently:Integration Options
Official SDKs
- Python SDK - Perfect for data science and backend applications
- JavaScript SDK - Ideal for web applications and Node.js
AI Framework Integrations
- LangChain Integration - Use SearchScraper in your LLM workflows
- LlamaIndex Integration - Build powerful search and QA systems
- CrewAI Integration - Create AI agents with search capabilities
Best Practices
Query Optimization
- Be specific in your prompts
- Use descriptive queries
- Include relevant context
- Specify time-sensitive requirements
Schema Design
- Start with essential fields
- Use appropriate data types
- Add field descriptions
- Make optional fields nullable
- Group related information
Rate Limiting
- Implement reasonable delays between requests
- Use async clients for better performance
- Monitor your API usage
Example Projects
Check out our cookbook for real-world examples:API Reference
For detailed API documentation, see:Support & Resources
Documentation
Comprehensive guides and tutorials
API Reference
Detailed API documentation
Community
Join our Discord community
GitHub
Check out our open-source projects
Ready to Start?
Sign up now and get your API key to begin searching and extracting data with SearchScraper!